
Hi, I'm Eric.
I’m an avid world traveler, photographer, software developer, and digital storyteller.
I help implement the Content Authenticity Initiative at Adobe.
Hi, I'm Eric.
I’m an avid world traveler, photographer, software developer, and digital storyteller.
I help implement the Content Authenticity Initiative at Adobe.
16 April 2024
This week I’m attending the 38th biannual Internet Identity Workshop, which is one of the most valuable conferences I’ve encountered in any professional space. As the name might suggest, the topics are largely around how to express human and organizational identity in digital terms that respect privacy and security. When I attended the previous IIW last fall, I wrote about it in real time as the conference was in progress. That format worked well for me and received a lot of compliments, so I’m attempting it again this week.
I’m part of a team at Adobe that is dedicated to helping content creators and content consumers establish genuine connections with each other. We do this through three organizations that we’ve helped to create:
Content Authenticity Initiative: CAI is a community of media and tech companies, NGOs, academics, and others working to promote adoption of an open industry standard for content authenticity and provenance. The CAI does outreach, advocacy, and education around these open standards. Content Authenticity Initiative is also the name of the business unit of which I’m a part at Adobe through which we participate in all three of these organizations, develop open source and open standards, and guide implementation within Adobe’s product and service suite.
Coalition for Content Provenance and Authenticity: C2PA is a technical standards organization which addresses the prevalence of misleading information online through the development of technical standards for certifying the source and history (or provenance) of media content.
Creator Assertions Working Group: CAWG builds upon the work of the C2PA by defining additional assertions that allow content creators to express individual and organizational identity and intent about their content.
I recently published an article titled Content Authenticity 101, which explains these organizations and our motivations in more detail.
IIW is held at the lovely Computer History Museum, which recounts the formative years of our tech industry. CHM is located in Mountain View, California, right in the heart of Silicon Valley.
I’ll share a few photos of the venue and the conference. My non-technical friends might want to bow out after this section as it will rapidly descend into lots of deep geek speak.
IIW is conducted as an “unconference,” which means that there is a pre-defined structure to the conference, but not a predefined agenda.
There are several variations on how the agenda gets built at an unconference. In IIW’s case, there is an opening meeting on each morning in which people stand up and describe sessions they’d like to lead that day. Then there’s a mad rush to schedule these sessions (see photo below) and we all choose, in the moment, which sessions to attend.

You might think that not having a predefined agenda would mean that the topics that occur could be flimsy or weak or low in value. In practice, the opposite is true. Both times I’ve attended this conference so far, I’ve had to make very difficult choices about which sessions not to attend so I could attend something else which was also very compelling.


With that, here is my description of the sessions I’m attending this time around:
Eric Scouten
I gave an introductory session titled Content Authenticity 101. We had about 30-40 people attend with lots of great questions about identity binding, signature mechanisms, and trust list.
did:tdwStephen Curran
Simplified version of DID with key rotation sponsored by BC Government.
<1000 lines of code to implement.
Intended to incorporate key concepts from KERI, but not take on the complexity of KERI.
Compatible with did:web!
Still to do: DID challenges.
Ohhh, wait … they have DID issuer trust chaining built in via /did/whois.
Heading to standardization (IETF likely) soon.
Links:
Matt Miller
Discussion about image theft and appropriation of identity.
“Overwhelm with the positive (trust signal); ignore the negative.”
Discussion about how to have trust in anonymous or pseudonymous content.
Some misconceptions I observed:
“I think you just said it sucks to have to make our own (trust) decisions.”
Alethia combines signature with DNS.
TurnItIn anti-plagiarism tool used in academia.
Timothy Ruff

DTV founded in 2019 to launch new SSI businesses.
2022-2024 incubating more startups in health care, trade, securitization, and more.
Business model challenges:
Suggestions:
“The technology in this space has a half-life of about five years.” 🎤 drop
Eric Scouten
I led a discussion about some of the interesting challenges we’re facing as we work to bind varying kinds of credentials to the CAI/C2PA/CAWG ecosystem.


Some discussion in response to my slides:
Scott Perry approached me afterwards and encourged me to review the ToIP Issuer Requirements Guide for Governance Frameworks for Verifiable Credentials. This document provides guidances for several of the thorny questions I raised in the session.
Mathieu Glaude, Tim Bouma, Jesse Carter
Check for link and spec after meeting.
Design goal: How can we take a friendly DID method (did:web) and add high assurance without adding a lot of complexity.
Problem statement: Idetifiers today are either easy to recognize or easy to verify but rarely if ever both.
Solution: Develop formal guidance for formally binding DID with DNS infrastructure.
Starting from did:web:issuer.trustregistry.ca, how can we provide machine-verifiable assertions?
No new infrastructure required.
Tim Bouma: Think of this as 2FA for DID docs.
Using existing DNS record fields and DID document content that are already standardized.
Follow-up: What is Canonical JSON?
Replicate key portions of the DID document (proof?) in DNS records as a safeguard against server compromise.
Look at DNSViz, a tool for verifying the status of a DNS zone.
Links:
Current implementations:
Kim Hamilton Duffy, Otto Mora
Goal: Develop and publish credential schemas to support interoperability.
Outputs:
Viewpoint: Credential schemas provide improved interoperability, discoverability, ease-of-use, and standardization.
Some examples they’re working on:
Audience suggestion: DIF should create guidance on how to create new credential types. (Strong agreement from me!)
Some examples of credential schema registries:
DIF motivation to promote alignment in credential type.
Pia Blumenthal, Eric Scouten
Notes adapted from audience member Zaïda Rivai. Thank you!
Pia raised several discussion questions:
Alex: UI/UX in Cheqd have the same issue in the team how to display VC easily.
Pia: How much verification is needed to provide trust? Single? Proof who you are? Do you have a list of best practices?
Alex: Trust is diagonal.
Judith (ToIP): How we do everything, but from a specific context, how is that governed> How is this covered today in different media outlets? And then getting to the point of trust registries: “This ecosystem recognizes X and this ecosystem trusted Y.”
Lorie: Also a legal problem but onboarding legal frameworks, signatures exist. That is one moving level. KYC is also well known and describe a level of trust is a different thing. But like Alex is the sum of all the parts.
Drummond: Don’t get enough UX designers. Gen team is leaning into this. Most of the technical questions are answered, but all are about UX. Literally same as you (Pia) put up here. One context, one specific service. It is a hard problem.
Cam: Is this a problem that needs to be solved? Enough user basis, real problem. Should we prioritize or other problems that have more user aid.
Riley: Interested whether media platforms have different trust requirements. Twitter has their platform and they may be okay with strong verification checkmark but not okay if it would be only oAuth. Is there a mechanism for a platform the users consuming through, tailored the trust decision? Wonder whether the platforms and media whether they want to make the trust decisions for the users. Something that’s considered?
Pia: Progressive disclosure. Implementer chooses what information to highlight. Level 1 and 2. People don’t necessarily want to see bugs (overlay icons) over top of their content. Up to the implementer to figure what the right information is for that audience. At Adobe, we prioritize AI disclosure. When AI generated or edited with gallery mixed creator work. Might not be the case somewhere else. In C2PA implementations we created a tiered experience. Some only show how it’s created, other show who is involved, the audience has to understand that it’s this model (progressive disclosure).
Judith: Think that UI specifically is important for the end user to understand. Getting the interaction patterns, UX is very difficult. UX group, digital wallet survey and coming to what is the next project?
Alex: Maybe there should also be a creator reputation WG: completely separate goal to assertions.

Drummond Reed, Eric Scouten, Scott Perry, Stephen Curren


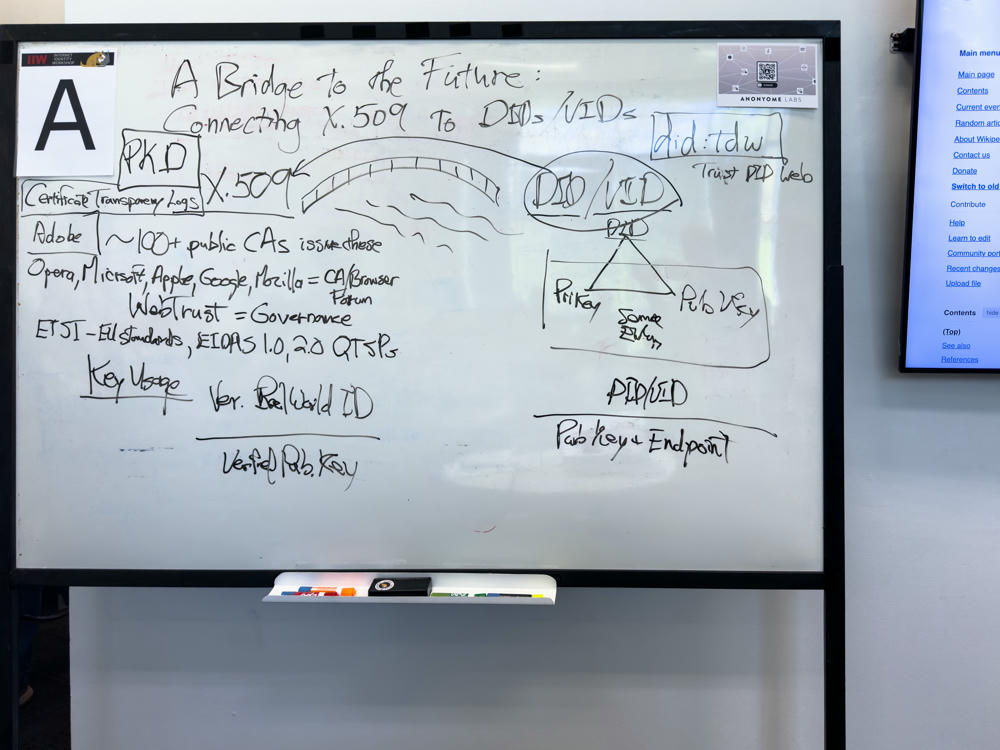
Scott introduced the CA mechanism which is used by browsers to make the trust/don’t trust decision in HTTPS interaction. Each browser has its own governance mechanism, but they work together via the CA Browser Forum to share governance requirements known as Web Trust.
EU has its own trust infrastructure via ETSI. EU has a certification structure driven by EIDAS 1.
C2PA is evolving its own distinct trust infrastructure via its Trust List Task Force.
Browsers have worked together to require a control process for certificate issuance tracking known as Certificate Transparency Log, meant to prevent fake CAs from pretending to have issued certs.
DID = Decentralized Identifier (W3C standard ~2 years ago). Ties public key, private pair, and identifier. Many but not all DID methods allow continuity of identity across private key rotation.
VID = ToIP concept, related to DID, but removing some of the syntactic requirements.
VID is an effort to reopen the tent.
In X.509, issuer is necessarily always a CA as a means of enforcing the governance rules. DIDs are much more open in issuance. X.509s could be considered VCs, but in a different format and with stricter governance.
DIDs and VCs split the human readable part vs the machine-readable part.
DIDs allow governance to be added post-hoc. A DID can be attached to a VC at a later point depending on the governance or requirements of the DID holder.
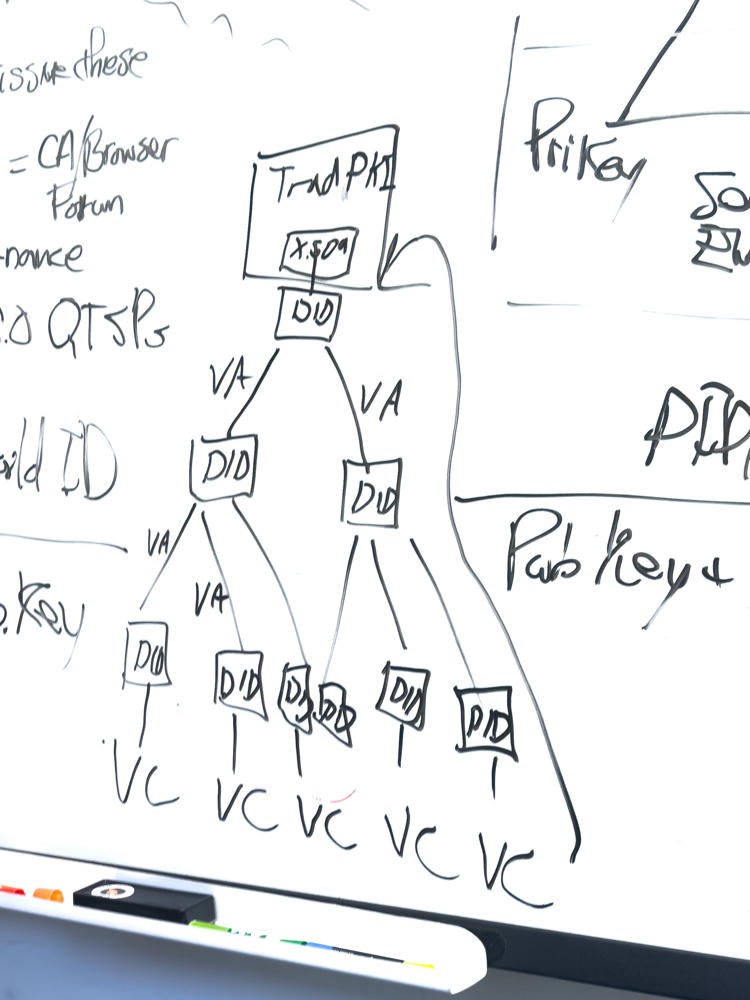
Challenge that ToIP did:x509 TF has encountered: How do you retain a persistent identifier given that X.509 certs have to be periodically rotated? Maybe we don’t.
Maybe the answer is to invert that. What if we encode a DID into X.509 subject alternative name (SAN) or similar field?
CA may or may not be able to use SAN depending on type of cert requested.
So can we describe a way for CSR (Certificate Signing Request) to include proof of control over the private key associated with the DID?
Lucy Yang and her company did a conversion of X.509 to DID a few years ago as part of WHO COVID credentials effort. (TO DO: Add link to this effort if possible.)
EBSI is working toward this using exactly this approach. (Follow up with Alex Tweeddale.)
California DMV is referencing X.509 chain via x5c parameter in a did:jwk.
Look into EBSI verifiable accreditation mechanism. Alex Tweeddale sent a link to a presentation he did regarding EBSI trust chaining.

Subscribe to my free and occasional (never more than weekly) e-mail newsletter with my latest travel and other stories:
Or follow me on one or more of the socials: